
US statistics
by Don Brockett

So, you want to jump into the data on Brocketts in the U.S.? WELCOME!!! Let’s go.
The objective of this page is to provide some numbers, together with an understanding of the data and how the numbers were derived (both are important). Many “statistics” and numbers in genealogy aren’t crisp and specific – it’s more like deciding where the edge of a soft cloud ends. By no means is this a final product. It’s a starting point that we’ll continue to work on and refine over time. Current topics include:
What is a Brockett?
Wading through the data quagmire</a
Sifting Through Past U.S. Census Data
Estimates of Brocketts now
Thoughts for additions to this page
Archivist’s note:Read more
What is a Brockett?
Lots of different “Brockett” creatures’ roam around in the U.S. – with a variety of similar names – Brocket, Brockett, Brockette, and various other spellings. The scramble of names in the graphic below shows 10 of the most common variants – various sources and methodologies identify up to hundreds of potential others. Most of us would like to focus on our actual genetic ancestors and relatives, and to ignore the rest. This would be a relatively easy task if a Brockett were always a Brockett, and a Barkett were always a Barkett (and so forth) – but in fact that isn’t nearly the case. Some Barkets may be Brocketts and some Brocketts may be Pricketts. We’re not alone in this situation – virtually all other surnames have a similar issue.

Do you know which one, or ones, are of interest or relevant to you? For the remainder of this page ‘Brockett’ will be used as a generic, rather than specific, term. Where I mean a strictly genetic-relationship, Brockett is in brackets [Brockett] (a pun – yes, partially).
Some people might want to know how many [Brocketts] currently live in the U.S. But which Brocketts do we count? The ESSENTIAL first step in answering that question is to determine (as best we can) who IS and who ISN’T a [Brockett]. People who are seeking a quick and simple answer don’t understand either the question OR the data. Deciding who/what is a [Brockett] has widespread impact on many things in genealogy. The results of using a very specific surname definition are often much different quantitatively (and in other respects) than for a more open/”fuzzy” definition. A very specific definition is flawed in that it excludes [Brocketts] who were misidentified with a different name. And a very fuzzy definition brings in hordes of [Brockett] “pretenders” who somehow must be laboriously culled out. Somewhere in-between is the best (but probably not the exact) answer.
The [Brockett] ancestors arrived in the U.S. already with multiple surnames, and the variety has expanded significantly while here. The population of [Brockett] immigrants is estimated to have grown something like 100-fold.
Why so many surname variants? Life is far from exact or precise. For many reasons, when humans try to communicate verbally or in writing, there’s often a mismatch between what was said/sent and what is heard/received. Then, what is written down by the receiver may not be exactly what they saw or heard – and/or their handwriting may be unclear and subject to further misinterpretation by someone else. The adage of Murphy’s law (or Sod’s law in the UK) applies all too often: “Anything that can go wrong will go wrong”. The errors accumulate and potentially build on each other over time – something like the game of passing a story around a circle of people to see how it mutates. When it comes to surnames, with only the exception of the census transcribers (described below), it is rare for mistakes to be found and corrected years or decades later. So, we are forced to live with the growing multidirectional distortion, even though it makes genealogical work much more challenging. We can do our part to limit this by being almost fanatical about the accuracy of our own work.
We’ve even heard stories of surnames being intentionally altered slightly to differentiate one group (presumably less “socially elite”) from another.
In the end, precise population numbers may be impossible to develop. The key thing is to make estimates based on consistent data sources and processing methods – and to diligently document our data sources and research processes. Good scientific research is thoroughly documented so it can be understood and repeated. The documentation is equally as important as the research results. Genealogy is SUPPOSED to also be a science – not a parlor game. We need to more closely emulate geology, psychology, entomology, meteorology, and so forth in our work.
Out in the woods a black bear looks different than a brown or grizzly bear. And skunks, raccoons and beavers all look different. So do deer, elks, and moose. But there’s no visual or other sensory difference between a [Brockett] and a Brockett (or for that matter, from a Jones or Wright). And it’s quite possible that someone with Asian or Black features IS a legitimate [Brockett]. We’ve had to rely on historic records that are difficult to find, hard to decipher, and in varying degrees of completeness and decay. We need some help.
The industrial revolution happened in the 19th century. Another very important revolution is taking place in the 21st century – DNA. Science is coming to our rescue in genealogy by offering DNA, where many of the sources of errors and ambiguity in manually produced records are circumvented. But regardless of all the publicity, DNA testing is still in its extreme infancy. According to a February 2018 industry estimate, 12 million people have been tested – well less than 0.2 % of the Earth’s population. Despite some bad recent PR, 2017 was a year of huge growth in testing. “More people took genetic ancestry tests last year [2017] than in all previous years combined.” And the science of DNA will be experiencing major improvements in the coming years. There is an enormous opportunity – no wonder we see so many ads for the product/service. The cost of testing is nominal, considering how much time/work would be needed to get the same information otherwise.
So, at some point in the future, when a large enough part of the population has been tested, DNA will likely become the gold standard for accuracy in genealogical research. Right now, it’s a huge help in a small way.
The advantage of DNA is things usually don’t get contorted. Data isn’t “maybe this”, “maybe that”, or “maybe something else”. DNA can work together with reliable documented data to fill gaps in heritage where no solid written data exists. There’s lots of promise, but for the most part right now, the best we can do is continue to shuffle papers – vigorously, tenaciously, knowledgeably, and open-mindedly – and with perhaps a smattering of skepticism as in the Missouri state motto of “Show-Me”.
A lot of the work in genealogy is like deciding which squarish-looking pegs really belong in the roundish holes – it’s subjective. For example, how much secondary or tertiary evidence do we need to substitute for solid primary documentation? Perhaps, in a way, the graphic below expresses the near-term progress we can hope for – mostly the same data, but better organized and understood.

Wading through the data quagmire
The U.S. Census Bureau produces an onerous volume of data. Most of us need help in plowing through the data to find the results we’re seeking. So, we turn to organizations like Ancestry.com, Archives.com, Geneology.com, or several others for help. When we do a surname search of U.S. Census data, the better online search engines allow us to be more exact, or less (“fuzzier”), as to the amount of name variation allowed. The best among them seems to be Ancestry.com who offers 4 versions of its search algorithms, or filters. These are termed “exact”, “exact & similar”, “sounds like and similar”, and “broad”. Using those filters on the 1940 U.S. Census Data with the surname Brockett as the only search term returns the following results of records found:
| Filter | Records Found |
|---|---|
| Exact | 2,014 |
| Exact & similar | 2,512 |
| Exact, sounds like and similar | 2,842 |
| Broad | 170,004 |
So, sequentially easing-off from the strictest (exact) definition of who is a [Brockett] understandably adds more people, but the number of records found is still subjectively logical/believable – at least until we reach the 4th almost ‘all-comers’ level. Understandably, for good reason, even the ‘exact’ filter includes some surnames spelled differently than Brockett. We’ll explain that further down on this page.
Just how, and how much, to open-up to non-exact variants of a surname is highly subjective. Different rules may be appropriate for different end-use purposes and for different data sources. Our intent here is to try to focus on [Brockett] as much as we can.
A close look at research from various sources where the surnames considered are listed, shows the lists to range from slightly to markedly different. Some people choose to be absolute “purists” – others want to leave “no stone unturned”. How would YOU choose to treat “Prickett” or “Rockett”? When using research done by others, try to understand both the why and how of what they did.
People approach genealogy research from a variety of perspectives. Most want to objectively discover who their ancestors were. A few are out to prove something – that they are a relative of the Queen, that they qualify for the DAR, that their husband’s great uncle Alphonse really was a scoundrel, or whatever. The latter group seem to be more inclined whatever information they can get, or to accept skimpy or undocumented evidence (“Aunt Martha said it was so”). But their results (often presented as a a family tree) may appear right alongside the work of people who have been diligent and meticulous researchers. Take care.
Ancestry.com is an invaluable resource for genealogy work because they have done so much advance scouting and data compilation work for us. They are likely the biggest (and subjectively the best) – but they are definitely not perfect. They have lots of room for improvement to existing products and services, and lots of new offerings in their future. The huge influence of the organization, both directly, and through its host of subsidiaries and affiliated companies, is important to understand. We’ve identified more than 25 genealogically-related companies that live under the Ancestry umbrella. Government agencies like Census and National Archives often partner with Ancestry. Some of the other online genealogy websites are good too, but none of the other online players have nearly so much reach and influence as Ancestry.
Almost regardless of how avid a family history sleuth we are, most of us choose not to pay for 4-10 online subscriptions to genealogy websites that offer very similar results. Nor do we have the patience or discretionary time to look again and again through the same “pile of coal” to see if any new diamonds have developed.
Like with most things in life, the data from Ancestry (or wherever) must be approached carefully and thoughtfully. For example, on their website, Ancestry shows several interesting data tidbits about the Brockett family history. One shows the average Brockett lifespan from 1948 to 2004. Unfortunately, that data doesn’t mention or factor-in the unnatural negative impact that World War 2 likely had on average lifespans. To the extent possible, we’d like to see the full history of this data since the Census started.
Ancestry shows the following maps of where the Brockett families were in the U.S. in 1840, 1880 and 1920.2 See the progression by clicking the >.
We’ll try to update this with more recent data in later editions of this page. The data is probably on the Census somewhere, but so far, the more recent data has escaped our search efforts. Based on these maps, it isn’t surprising that the most common Brockett occupation in 1880 was farming. We also would like to know more about recent Brockett occupations.
Ancestry.com has several relatively general articles on surname filters. But an unfortunately, when doing a surname search on Ancestry we don’t know the details of the filters used to produce our results. Presumably that situation reduces quibbling about what the filters “should have been”, but it also leaves a feeling of uncertainty. The Ancestry filters may be quite complex, but we would like to have a shot at understanding them, so we could compare with the filters used elsewhere. Given the choice, I’d rather deal with a known that I disagree with slightly, than a complete unknown.
Forebears.io used to give a list of 135 [Brockett] surname variants. In a recent major updating of their website, the number was inexplicably reduced to only 25. It appears the difference is due to a change of focus from the world to the U.S. only. Selfishly, we applaud that. But close inspection of the remaining names raises some questions about excessive severity of their exclusions.
There are several other surname variant websites, but most don’t give information as to how their list was produced, or for what area of the world it applies to. The NameThesaurus website explains their algorithms to some extent on their FAQ page. And the size of their list is more manageable – 231 names. But the focus is worldwide, so many are irrelevant when the U.S. is the focus.
Soundex is a rather rough tool originally developed in the early 1900s to address the issue of phonetically similar names (it doesn’t address letter transpositions and the many other forms of non-verbal error sources). A good discussion of the tool, together with sources of software, can be found on the FamilySearch website.3 We found that Soundex produces a huge list of variants for [Brockett] (11891) – far more than is logical (unless we choose to consider singular data errors in the U.S. population of 300+ million). And it’s far more than we can realistically deal with given our limited resources. Additionally, it isn’t specific. Several variations of the original tool have been developed. MetaPhone is a recent (1990) update of Soundex, but still produces so many possibilities (2152) they can’t be dealt with either. More quantity is not what we need – better quality is.
Beider-Morse Phonetic Matching came along in 2008 with several innovative new processing steps that reduced both false positives and false negatives. Among these were determining the language from the spelling of the name, and then applying pronunciation rules based on that specific language. It also considers the entire name rather than just some initial portion of it.
This game is hard to win – there are SO many “catch-22s”. It’s easy to understand why many people either just accept what they find – or quit looking. Hope is on the way.
This extremely tedious “names-game” could easily (and hopefully WILL) slide into the background in the future as DNA testing becomes ever more common. With DNA, the name doesn’t matter nearly so much as the marker values. DNA could even provide us with a resource to help in sorting out the surname variants. DNA matching has become a very hot topic of discussion on the internet.
For a DNA participant, the first steps of testing are rather trivial – usually just a swab on the inner wall of the mouth. But once the test is complete, understanding and using the results can be daunting. There’s usually no “AHAAA!!!” or “Eureka!!!” – “all my ancestry is revealed”. It may be hard for many people to see the value of the results, and they question why they participated. A lot of reading and self-education needs to be done on the intricate and rather technical nooks and crannies of DNA. My career and education were a dual effort in engineering and marketing – and I’m a motivated supporter of genealogy and DNA. But I admit to having a difficult time understanding the intricacies of DNA. My priorities and discretionary time just don’t permit the study needed. With the help of some very gracious and knowledgeable people, DNA has opened some previously closed doors to my ancestry – I’m glad I participated. The first company that comes along with the smarts to help us “people-on-the-street” better understand the individual value of DNA will capture a lot of attention.
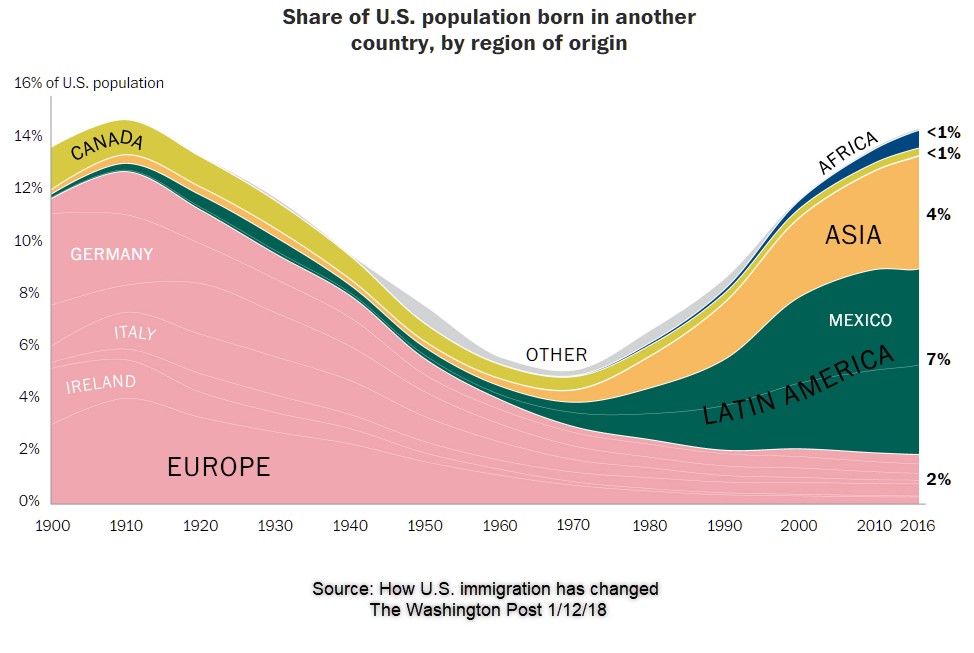
One way to test data is to see if it’s subjectively believable. For example, does it make sense that any of the first 3 search results from the 1940 Ancestry searches above could have grown to the 2014 Forebears estimate of 3627? That would be an increase ranging from 28-80%. According to census data, during roughly the same period of time, the overall population of the U.S. grew by 342%. As the chart below shows, there was a decline, then a major surge in the amount of immigration to the U.S. during that time, but immigration specifically from Europe (the source of our [Brockett] ancestors) declined drastically. So, [Brockett] immigration during that time was probably small relative to the overall picture – far below the 342% level. Therefore, the percent increase for Brocketts seems plausible – at least in a rough sense. But the 170,000-figure for 1940 produced by the “broad” (fuzziest) filter seems grossly improbable and places a major question on its value. One might suspect that filter is closely related to Soundex.
The issue of erroneous census information isn’t just imagined or contrived. It happened to me. In the 1940 census, both my middle and surnames were butchered (Wendell Dane Brickett). Thankfully both my parents were assigned the same wrong surname. (We were easier to identify as a group than individually.) In addition, my [Brockett] grandfather in another state was recorded with a still different, but wrong surname. And in the censuses from 1850 to 1920, my great grandfather Brockett received 5 surname variants and also 5 given name variants. They were randomly mixed. It’s doubtful my family was singled-out for this kind of “special attention” from the Census Bureau. Census data simply doesn’t play nice.
An amusing personal example of misnaming sometimes happens when I go to a registration desk and they ask for my name. I give them “Don” because I’m generally known by my middle name. It says something when they write down “Dawn”. I’ll let you guess my thoughts – but I must be the ugliest Dawn on the planet.
In doing a quick scan through the results of even an “exact” search, one finds a significant number of Brockett variants. And some completely different names are found too (actual examples include: Zarnoth, Hathway, Veitz, Moore, and Wisener). The latter usually happens where the parents of a married Brockett daughter are living with her – for whatever reason. The lineage of a married Brockett daughter living apart from her parents is usually lost.
From the standpoint accuracy of aggregated data, it would be ideal to at least have the same number of erroneous inclusions as the number of erroneous omissions. I’d also find it ideal to win the lottery.
There are some wonderfully patient, detail-oriented people somewhere who transcribe the raw handwritten census data into a printed format. For one thing, that serves to keep us from going blind trying to read the original records. But arguably, their greatest contribution may well be in applying experience and intellect in their work as they try to identify errors, struggle with illegible writing, and suggest possible corrections. To quantify, approximately 7% of the 1940 Census records from the Brockett “exact” search on Ancestry.com had “Other Possible Names” notations supplied by the transcribers. More and more, optical character readers can take on some of the more mundane parts of data transcription, but the capabilities of a good human eye and mind win out when the going really gets tough. To fully appreciate the work that the transcribers do, you need to look at the original census records from a century ago (or even 1940) and consider reading them – accurately – for an 8-hour workday. ACCOLADES TO THEM!!
Sifting Through Past U.S. Census Data
We can’t quite put the census topic to bed quite yet. In 1790, the U.S. began collecting census data every decade. Being a census-taker in those early years must have been an extremely challenging, and sometimes outright dangerous job. Outside a few major cities, population density was low, roads were poor or non-existent, law enforcement spotty, travel times long, and restaurants and hotels rare. In addition, literacy of the general population was lower, hearing loss often went untreated, and the English spoken had many dialects. Native Americans probably had no more sympathy for census-takers than other ‘invaders’ – even though the census-takers were harmless and temporary.
As previously noted, data from the 1940 U.S. Census had many issues, but it’s hard to imagine the quality of the early data matched that of more recent censuses. Still, the census needed to get underway to provide information about the population and economy, and it did that—however crudely. Gathering and processing the data in the early days was a lot of tedious, hard, manual work. From 1880 and 1900, the ‘temporary’ Census Office was open almost the entire time between censuses. A permanent Census Office was finally established in 1902.
By 1940, the census had made major strides forward, but judging by the picture below, there was still a lot of room for improvement. On the bright side, at least the farmer didn’t have to shut down the engine on his tractor.

A census-taker interviews a farmer c 1940
The job of census-taking involves verbal communication – asking specific questions, then hearing and accurately recording the answers. It appears that very little, if any, reliance was placed on gathering information from written (especially printed) documentation. That alone sets the scene for LOTS of errors in the census data.
For example, if a census-taker happened to be of Hispanic decent and was interviewing someone (in English) who was a Russian immigrant, the problem is glaringly obvious. Almost the same sort of issue might apply to a New Englander talking with a Southerner. It would be interesting to hear a discussion among linguistic experts on this topic.
Literacy played a major role too. The provider of the information may not have known how to spell the names and places they were talking about and couldn’t help the census-taker. In 1870 about 80% of the population was considered literate vs 99% recently. In colonial times, literacy varied broadly by gender, geographic region, and economic class, but no objective data is available.
To further compound the verbal communication problems, the penmanship of the census-takers sometimes had limited legibility. That only worsens the issue of erroneous intake of verbal information. Then, to boot, if one of the parties had visual limitations and/or a hearing deficiency, we have ALL the ingredients for chaos.
Even the sense of smell may have been influenced the census-taker – as if they were a city-dweller assigned to work in a farming environment. One might wonder if the “older, but infinitely worldlier” saying might apply to a veteran census-taker – even today.
One might also ask what kind of person would take on a temporary job with so many issues to deal with?
Finally, as frosting on this untenable scenario, to collect data from such a large group of people in a timely manner, the census-takers must have also been under pressure to complete their tasks quickly. ‘Shortcuts’ in data collection were likely common. To be fair, most census-takers probably did the best they could under the circumstances. The reference book for 1940 enumerators was 88 pages long and about as easy/interesting to read as the fine print in a legal contract for dirt removal from a contaminated industrial site.
As a result of all of the above, the census data includes many errors – some minor, some major. So, anyone who expects census data to be highly accurate is seriously misleading themselves.
The description above is not meant to have you run away screaming – census data is still very useful, and one of the best tools we have for tracing our roots. But it should be used with caution and an understanding of the shortcomings.
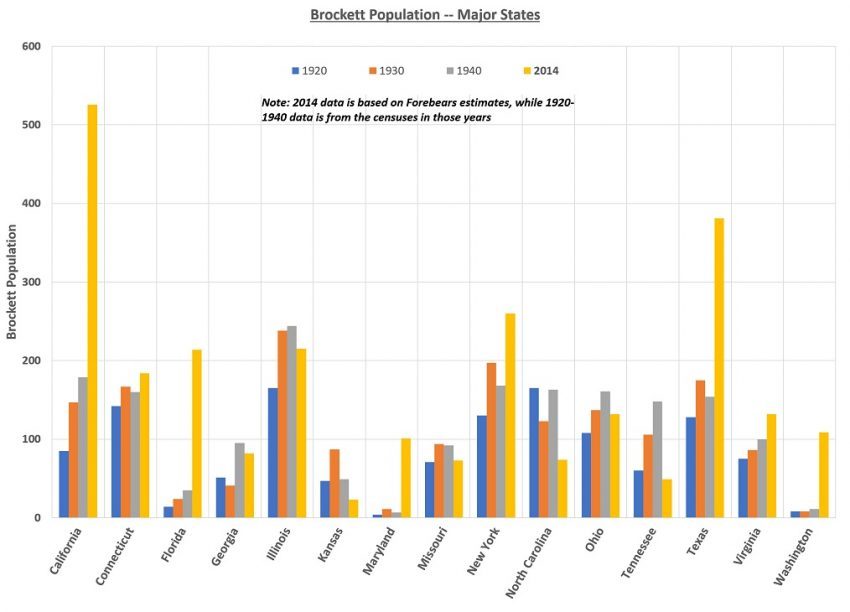
Another view of Brocketts is where they (we) have been moving to/from in the U.S. over the 1940-2014 period. That involves comparing leading states in 1920, 30 and 40 with the 2014 leaders, as in the 15-state chart below. Forebears data was used for 2014.
Brocketts Now
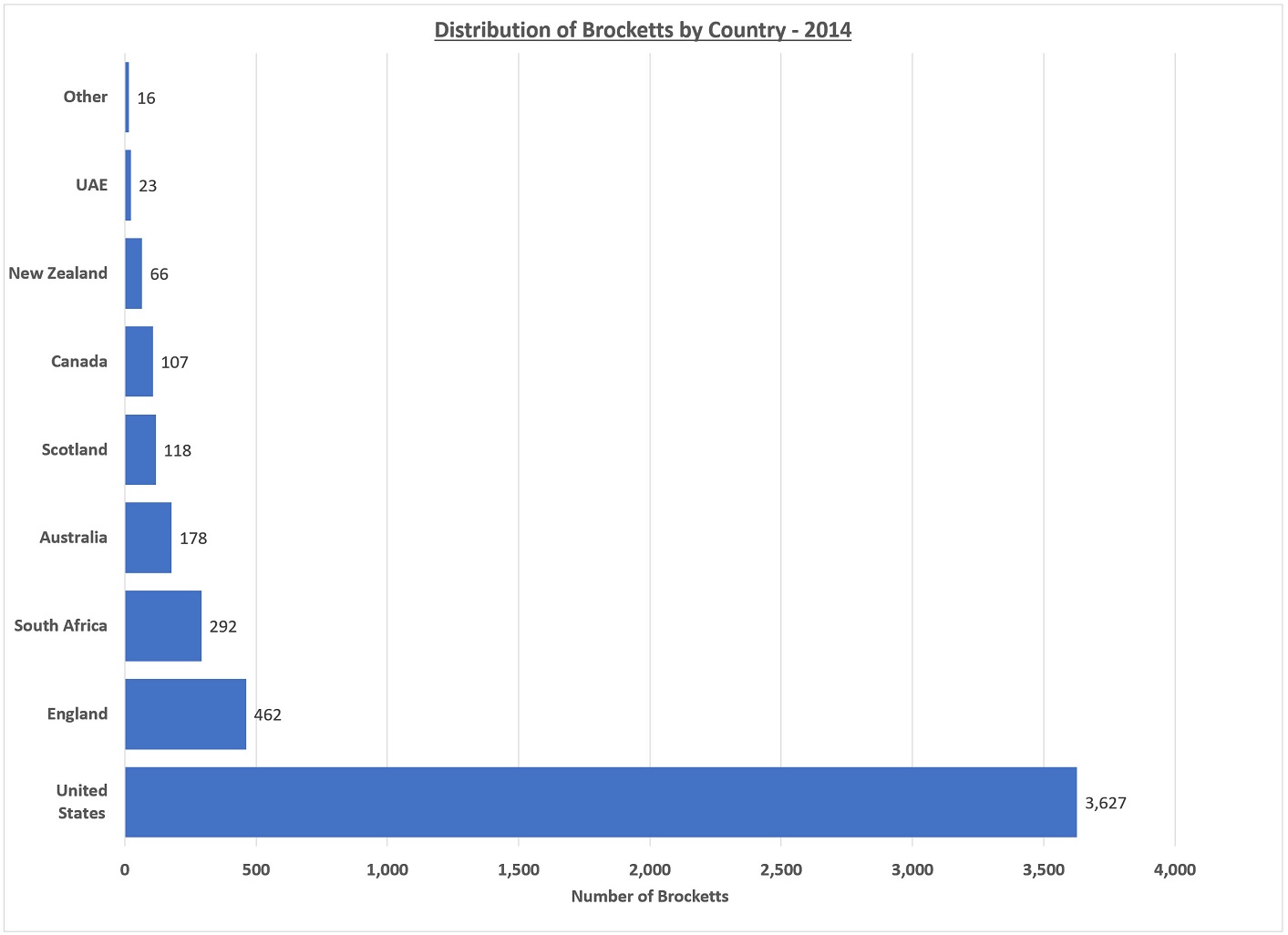
Forebears.io, a good genealogy reference source, lists 3627 Brocketts in the U.S. as of 2014. That’s about 74% of the Brocketts in the world by their estimates. Brocketts are listed in 18 other countries. According to them, Brockett is the 88,101 most common surname in the world. You can check their website4 or the chart below for details. Regrettably, there are a number of questions about the source of the data (which Brockett variants were included) and how the numbers were developed. But for now, they seem to be the best estimates we have.
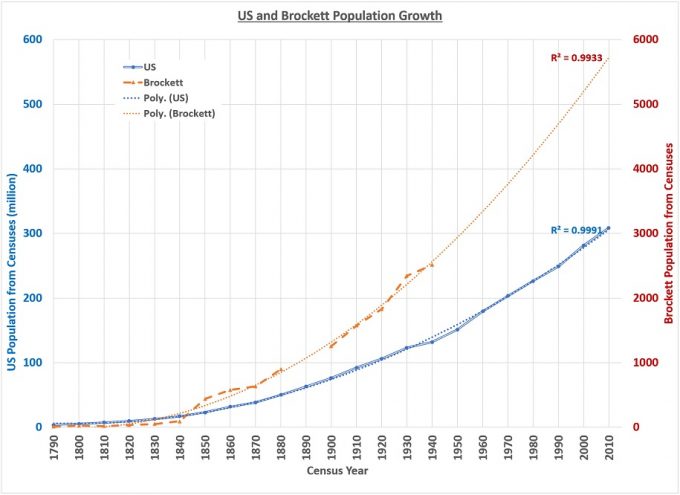
It’s always an uneasy feeling to look at estimates where no information on data sources or methodology are provided. So, here is our own effort to estimate the current population of Brocketts in the U.S.. We took the Brockett populations from the 1790-1940 censuses (as provided by the Ancestry.com ‘exact and similar’ search filter) and plotted them on a chart in Excel. Excel gives 6 main alternatives for calculating trendlines. We tried them all and found the second-order polynomial to be the best curve fit, with a very good R2-value of more than 0.99. We did the same thing for the U.S. total population data from the 1790-2010 censuses, and again found an R2 > 0.99 using the 2nd order polynomial trendline. Based on this trendline analysis, the Brockett population in the U.S. in 2010 would have been around 6000. That’s a subjectively “comfortable” number, generally in the same order-of-magnitude as the unsupported estimates made by Forebears.
Admittedly, there are lots of questions whether using this process is viable for projecting forward for 70 years based on census data. But so far, we haven’t found a better approach where data sources and the methodology used were disclosed.
The U.S. Census Bureau has all kinds of demographic information, some of which is only a year or so old.
But someone, somewhere in the history of the census decided that records having data about specific people should not be released until 72 years after the census was taken. As a result, the 1940 Census data was finally released in 2012. Presumably this was thought to potentially be a privacy issue if released sooner. Of course, DNA data has also recently been subjected to privacy concerns. My own curmudgeonly view of the reasoning for Census data is they thought most people wouldn’t outlive the 72-year period, and those who did survive would be too feeble to raise much of a fuss about the quality/accuracy of the data. Sorry folks – I did, I’m not, and I am.
Even though recent individual data isn’t available from the Census, there still is useful data that is aggregated down to the surname level. We have the full lists for 2000 and 2010 — 151,671 and 162,254 surnames respectively. The useful data for each surname includes rank, count, % white, % black, % Asian/Polynesian, % North American indigenous, % 2 or more races, and % Hispanic. The data for the 10 names in the “Brockett scramble” is shown in the table below—the figures are all percentages. To be absolutely clear, these percentages are the ethnic makeup of Brocketts as a whole group, and DO NOT apply on an individual basis.

Given the Anglo-Saxon origins of Brockett, this data may surprise some people. How could it be correct? There are several ways it likely happened — interracial marriages, slaves of Brockett slave-owners took their masters names, adoption, and so forth. Remember, a person can still be a [genetic-Brockett] even if their heritage is only ½, ¼, or ⅛ Brockett.
It would be great to have more recent individual Brockett data than from the 1940 Census. There are LOTS of ‘people-finder’ websites like Whitepages and Zabasearch where information on individuals can be found. One might think that data could be used to construct a detailed current head-count of Brocketts in the U.S. Checking several of these websites however, we found major issues. Some of the sites return only a limited number of search records, which is inadequate for several states like California and Illinois where the population of Brocketts is large. Many of the sites also have redundant or erroneous listings for an individual due to the different versions of the given names people use, different residence addresses over the years, misspellings of names, failure to realize a person has died, marriages, and so forth. And the problem of “when is a Brockett not a [Brockett]” still exists. In some instances, a person is included only because their record shows they live in the same residence as a Brockett. And usually a Brockett female who has married or remarried under a different name is lost. The sites also typically charge for using their services. With unlimited financial and manpower resources, the sites might be of limited value – we have neither of those resources, so we must pass.
A number of these ‘people-finder’ websites show the same numbers, so it’s our guess that several sites share data. None of the sites is forthcoming about the source of their data, nor how it was processed. So far, besides Forebears, we’ve found no resource for aggregated Brockett population data that appears to be reliable. The people-finder sites are primarily intended for finding specific people and may work suitably for that purpose.
In trying to develop some good estimates of the current [Brockett] population we’ve explored all the alternatives we know of. That includes theoretical models which haven’t provided precise enough estimates to be of much help.
One issue that often frustrates and perplexes genealogists is the dynamic character of the field. This is especially true since computers have entered the arena. Information used today may be different tomorrow or not even available.
We caution you to be especially careful of online family trees. The basis for many of the family trees often turns out to be 2nd or 3rd hand from other family trees where the information was poorly researched and/or documented, if at all. The basis can even be circular. When these kinds of a situations happen, errors are self-perpetuating. Aunt Martha may have been wonderful, but her recollection of facts from the past may not be. Or an ancestor may have had a hidden agenda and is only giving information favorable to their view of the world. And there’s no such thing as information being correct “because it’s published on the Internet”. One website recently viewed claimed the origin of Brockett was South African. Hmmm – the opiate epidemic is even showing in genealogy.
Thoughts for future additions to this page
This is the launch edition of this webpage. It is very much a work in progress. We intend to keep honing it to maximize its accuracy and usefulness to the viewer. While we try to use the most current or recent sources of information for this site, the internet is in a constant state of change and new discovery. So, something we include here may change 5 minutes after we reference it. We’ll try to keep things fresh and up-to-date but will sincerely appreciate your help in letting us know about anything that doesn’t work, has gone missing, or is otherwise out of whack. This will be a better site with your active participation. Thanks in advance.
Some ideas we have for topics in the future include the following, but we welcome and encourage you to give us your thoughts too. Answers, IF they can be found, usually take a significant amount of digging and communication (of course both of those take lots of time). Please be patient.
- How have immigration, migration, and family size contributed to the growth of Brocketts in the U.S.?
- Can we understand the ethnic aspect of Brocketts better?
- Who have the more notable (good or bad) Brocketts been?
- Did any population data exist before the 1790 “censuses”? Tax lists, State-wide land grants?
- What are the pros, cons, and limitations of the various genealogy research websites?
- Why is caution needed in collecting information about ancestors?
- In which surname variants are most [Brocketts] hiding?
- Even with its errors, how can census data best be used?
- What influences drove Brocketts to immigrate and/or migrate – religion, economics, family, oppression, politics, disease, …?
Your thoughts will help us use our energies most efficiently – PLEASE share them.
1. This file shows the variants:Brockett Surname Variants & Similar Names
2. Ancestry.com provides a good article on surname filters.5
Page Last Updated: July 16, 2022